






I. Introduction▲
Dans cet article, je vais vous parler des performances des programmes liées aux accès à la RAM, en mettant en évidence les cache lines.
L'article est scindé en trois parties : un peu de théorie, une expérience et l'interprétation de l'expérience. Le tout ne devrait pas vous prendre plus de sept minutes de votre temps.
J'utilise la microarchitecture Sandy Bridge d'Intel sur laquelle est monté un CPU i7 2600K.
II. Les mémoires▲
II-A. Les zones mémoire dédiées par core▲
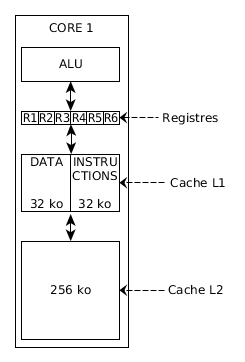
Il y a trois zones mémoire par core :
- Les registres : ce sont une trentaine de zones mémoire faisant partie de l'ALU et qui ont chacune un petit nom. Leur capacité varie de 32 à 256 bits.
La lecture et l'écriture dans un registre se fait en 1 cycle d'horloge seulement. Toute information issue de la RAM est stockée dans un registre avant d'être manipulée ; - le cache de niveau 1 : cette zone mémoire est divisée en deux parties distinctes de 32Ko chacune : le cache d'instruction et le cache de données. L'accès à ce cache prend 4 cycles ;
- le cache de niveau 2 : cette zone mémoire fait 256 ko. Un accès prend 11 cycles.
II-B. Les zones mémoire partagées par tous les cores▲
Ensuite, partagées par tous les cores, on a cela :
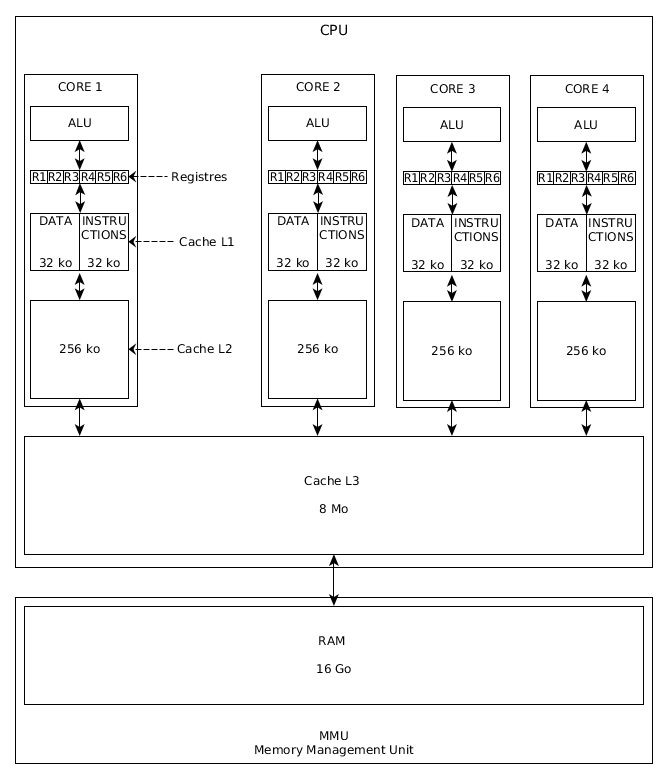
- le cache de niveau 3 : cette zone mémoire partagée fait 8 Mo.
Un accès prend 25 cycles.
Le cache de niveau L3 est physiquement dans le CPU ; - la RAM : ou DRAM pour être plus précis.
Ma machine a trois barrettes de DDR3-1066, pour un total de 12 Go.
Un accès RAM est difficile à mesurer, ça dépend de beaucoup de facteurs : différence du matériel, nombre de threads, à la localisation des données… Le truc à retenir, c'est qu'on change d'unité de mesure, on passe à la nanoseconde (10e-9 seconde). Dans un ordre d'idée, c'est dix fois plus lent que l'accès au L3.
Les accès RAM se font via le MMU (Memory Management Unit) ; - le disque : ce n'est pas vraiment une zone mémoire du CPU, puisque c'est le boulot de l'OS de mettre à disposition sur la RAM, les données du disque.
C'est également difficile à mesurer. Là encore, on change d'unité, on passe à la milliseconde.
Le ring sert de bus de communication entre les cores et le cache de niveau L3 ou la RAM.
II-C. Deux notions importantes▲
- Toute information en RAM devant être traitée par le CPU doit être recopiée dans le cache L1.
- Toute instruction devant être exécutée passe par le cache L1.
D'un point de vue temps d'exécution, ce qu'il faut retenir c'est que plus les données sont proches du CPU, plus ça dépote !
III. L'expérience▲
III-A. Le programme java▲
package jprudent.cacheLines;
public class Ex2 {
private static final int size = 512*1024*1024;
private static final long[] array = new long[size];
private static void benchMeLinear(int pas){
System.out.print(pas + "t");
long start = System.nanoTime();
for(int i=0; i<size; i+=pas){
array[i] = i * 3;
}
long end = System.nanoTime();
System.out.println((end-start) / 100000);
}
public static void main(String ... args) {
System.out.println("#Taille du tableau : " + size);
for(int i = 1; i<1024; i+=1){
benchMeLinear(i);
}
}
}
On met en RAM un gros tableau de 512 millions de long (0,5 G X 8 = 4 G).
Puis on le remplit linéairement N fois, en sautant N cases à chaque fois.
À chaque parcours, on affiche le temps d'exécution.
Au premier parcours, le pas vaut 1, le tableau est intégralement rempli.
Au second, le pas vaut 2, on remplit une case sur 2.
Au troisième, le pas vaut 3, on remplit une case sur 3.
…
III-B. Résultats▲
On exécute le programme :
java -Xmx8G jprudent.CacheLine.Ex2 > linear.dat
On génère un petit graphique avec gnuplot :
gnuplot> set logscale x 2
gnuplot> plot "linear.dat" using 1:2

Le temps de parcours est constant de 1 à 8. Si le programme parcourt toutes les valeurs ou s'il ne parcourt qu'une valeur sur 8, le résultat est identique.
Après 8, le temps de parcours devient proportionnel au nombre de valeurs parcourues.
Il est aussi coûteux en temps de parcourir linéairement 512 millions de valeurs que 64 millions de valeurs.
Le nombre de fois où l'on exécute i * 3 a un impact négligeable sur le temps d'exécution, sinon ce ne serait pas plat jusqu'à 8. Reste le coût d'accès à la mémoire qui pourrait expliquer.
III-C. Pourquoi 8 ?▲
J'ai mentionné que n'importe quelle information issue de la RAM doit au moins passer par le cache L1.
Détail important : les informations ne sont pas copiées octet par octet depuis la RAM vers le cache, mais carrément par blocs de 64 octets contigus mis en cache. Ces blocs de 64 octets s'appellent cache line.
Dans le cas du parcours du tableau avec un pas de 1 :
- Quand i = 0, l'instruction array[0] = 0 * 3 nécessite les étapes suivantes :
- On doit charger dans le cache les 8 premiers octets du tableau (1 long fait 8 octets) de la RAM vers le cache L1. On va dire que c'est l'adresse 0 (@0×00),
- En fait ce sont 64 octets qui sont copiés de la RAM vers le cache, la cache line couvrant les adresses 0×00 à 0x3F,
- Affecter la valeur 0 à @0×00 ;
- Quand i = 1, l'instruction array[1] = 1 * 3 nécessite les étapes suivantes :
- L'adresse @0×08 est déjà dans le cache (on l'a chargée en 1.1),
- Affecter la valeur 3 à @0×08 ;
- …
- Quand i = 7, l'instruction array[7] = 7 * 3 nécessite les étapes suivantes :
- L'adresse @0×38 est déjà dans le cache (on l'a chargée en 1.1) affecter la valeur 21 à @0×38
- Quand i = 8, l'instruction array[8] = 8 * 3 nécessite les étapes suivantes :
- On doit charger l'adresse 0×40 pour écrire dedans. Or, cette zone n'est pas encore remontée de la RAM,
- En fait ce sont 64 octets qui sont copiés de la RAM vers le cache, la cache line couvrant les adresses 0×40 à 0×79,
- Affecter la valeur 24 à @0×40.
Un long fait 8 octets. Une cache line fait 64 octets, donc on a besoin d'accéder à la RAM tous les 8 indices seulement. Une fois qu'un indice est accessible dans le cache, les 7 suivants sont aussi accessibles quasiment gratuitement.
Dans le cas où le pas vaut entre 1 et 8, il faudra monter, de la RAM vers le cache, l'intégralité du tableau. Et puisque monter des infos de la RAM vers le cache prend 99 % du temps, pour un pas de 1 à 8, le temps d'exécution est quasiment identique. Pour les autres cas, certaines parties du tableau ne sont jamais montées en cache. D'où le rapport temps / valeur du pas.
IV. Conclusion▲
Ce qui est lent, ce ne sont pas les calculs, ce sont les accès mémoire.
En comprenant le mécanisme de cache line on peut améliorer les performances d'un programme en réordonnant ses données et en profitant du fait qu'on charge les données par bloc de 64 ko dans le cache L1.
En extrapolant, on peut affirmer que le Single Responsability Principle n'est pas seulement un principe de design. En encapsulant des données sémantiquement proches, on a de grandes chances pour qu'elles se retrouvent dans la même cache line. Les calculs effectués en les combinant n'induisent pas de surcoût d'accès mémoire. C'est une bonne ligne de conduite pour de bonnes performances.
V. Références, inspirations et aller plus loin▲
Des expérience sur les caches par Igor Ostrovsky : article dont je me suis bien inspiré. Un must read si le sujet vous intéresse.
What every programmer should know about memory d'Ulrich Drepper. Une série d'articles très techniques pour en apprendre davantage sur la mémoire.
La plate-forme de trading haute performance LMAX utilise de telles optimisations. Mr Fowler en parle largement, et vous devriez trouver de nombreux pointeurs chez Novencia.
VI. Remerciements▲
Cet article a été publié avec l'aimable autorisation de la société Arolla. L'article original (A la découverte des Cache Lines) peut être vu sur le blog/site de Arolla.
Nous tenons à remercier Jacques THÉRY pour sa relecture orthographique attentive de cet article et Régis Pouiller pour la mise au gabarit.